
 Michal Marcinkiewicz
810bcf375e
[resnet/mxnet] Apply horovod patch for hvd init
Michal Marcinkiewicz
810bcf375e
[resnet/mxnet] Apply horovod patch for hvd init
|
2 lat temu | |
|---|---|---|
| .. | ||
| img | 4 lat temu | |
| scripts | 6 lat temu | |
| Dockerfile | 3 lat temu | |
| LICENSE | 6 lat temu | |
| README.md | 3 lat temu | |
| benchmark.py | 3 lat temu | |
| benchmarking.py | 6 lat temu | |
| dali.py | 2 lat temu | |
| data.py | 6 lat temu | |
| fit.py | 2 lat temu | |
| global_metrics.py | 4 lat temu | |
| imagenet_classes.py | 6 lat temu | |
| log_utils.py | 3 lat temu | |
| models.py | 6 lat temu | |
| requirements.txt | 4 lat temu | |
| runner | 3 lat temu | |
| train.py | 3 lat temu | |
README.md
ResNet-50 v1.5 for MXNet
This repository provides a script and recipe to train the ResNet-50 v1.5 model to achieve state-of-the-art accuracy, and is tested and maintained by NVIDIA.
Table Of Contents
- Model overview
- Setup
- Quick Start Guide
- Advanced
- Performance
- Release notes
Model overview
The ResNet-50 v1.5 model is a modified version of the original ResNet-50 v1 model.
The difference between v1 and v1.5 is in the bottleneck blocks which require downsampling. ResNet v1 has stride = 2 in the first 1x1 convolution, whereas v1.5 has stride = 2 in the 3x3 convolution.
This difference makes ResNet-50 v1.5 slightly more accurate (~0.5% top1) than v1, but comes with a small performance drawback (~5% imgs/sec).
This model is trained with mixed precision using Tensor Cores on Volta, Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results 3.5x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
Model architecture
The model architecture was present in Deep Residual Learning for Image Recognition paper. The main advantage of the model is the usage of residual layers as a building block that helps with gradient propagation during training.
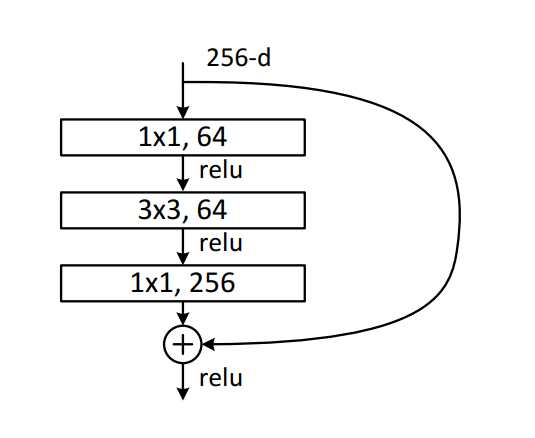
Image source: Deep Residual Learning for Image Recognition
Default configuration
Optimizer
- SGD with momentum (0.875)
- Learning rate = 0.256 for 256 batch size, for other batch sizes we linearly scale the learning rate
- Learning rate schedule - we use cosine LR schedule
- Linear warmup of the learning rate during the first 5 epochs according to Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.
- Weight decay: 3.
0517578125-05 (1/32768) - We do not apply WD on batch norm trainable parameters (gamma/bias)
- Label Smoothing: 0.1
- We train for:
- 50 Epochs - configuration that reaches 75.9% top1 accuracy
- 90 Epochs - 90 epochs is a standard for ResNet-50
- 250 Epochs - best possible accuracy. For 250 epoch training we also use MixUp regularization.
Data augmentation
For training:
- Normalization
- Random resized crop to 224x224
- Scale from 8% to 100%
- Aspect ratio from 3/4 to 4/3
- Random horizontal flip
For inference:
- Normalization
- Scale to 256x256
- Center crop to 224x224
Feature support matrix
| Feature | ResNet-50 MXNet |
|---|---|
| DALI | yes |
| Horovod Multi-GPU | yes |
Features
The following features are supported by this model.
NVIDIA DALI NVIDIA Data Loading Library (DALI) is a collection of highly optimized building blocks, and an execution engine, to accelerate the pre-processing of the input data for deep learning applications. DALI provides both the performance and the flexibility for accelerating different data pipelines as a single library. This single library can then be easily integrated into different deep learning training and inference applications.
Horovod Multi-GPU Horovod is a distributed training framework for TensorFlow, Keras, PyTorch, and MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use. For more information about how to get started with Horovod, see the Horovod: Official repository.
Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of Tensor Cores in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using mixed precision training requires two steps:
- Porting the model to use the FP16 data type where appropriate.
- Adding loss scaling to preserve small gradient values.
The ability to train deep learning networks with lower precision was introduced in the Pascal architecture and first supported in CUDA 8 in the NVIDIA Deep Learning SDK.
For information about:
- How to train using mixed precision, see the Mixed Precision Training paper and Training With Mixed Precision documentation.
- Techniques used for mixed precision training, see the Mixed-Precision Training of Deep Neural Networks blog.
Enabling mixed precision
Using the Gluon API, ensure you perform the following steps to convert a model that supports computation with float16.
Cast Gluon Block‘s parameters and expected input type to float16 by calling the cast method of the Block representing the network.
net = net.cast('float16')Ensure the data input to the network is of float16 type. If your DataLoader or Iterator produces output in another datatype, then you have to cast your data. There are different ways you can do this. The easiest way is to use the
astypemethod of NDArrays.data = data.astype('float16', copy=False)If you are using images and DataLoader, you can also use a Cast transform. It is preferable to use
multi_precisionmode of optimizer when training in float16. This mode of optimizer maintains a master copy of the weights in float32 even when the training (forward and backward pass) is in float16. This helps increase precision of the weight updates and can lead to faster convergence in some scenarios.optimizer = mx.optimizer.create('sgd', multi_precision=True, lr=0.01)
Enabling TF32
TensorFloat-32 (TF32) is the new math mode in NVIDIA A100 GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
For more information, refer to the TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
Setup
The following section lists the requirements that you need to meet in order to start training the ResNet-50 v1.5 model.
Requirements
This repository contains Dockerfile which extends the MXNet NGC container and encapsulates some dependencies. Aside from these dependencies, ensure you have the following components:
- NVIDIA Docker
- MXNet 22.10-py3 NGC container Supported GPUs:
- NVIDIA Volta architecture
- NVIDIA Turing architecture
- NVIDIA Ampere architecture
For more information about how to get started with NGC containers, see the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- Getting Started Using NVIDIA GPU Cloud
- Accessing And Pulling From The NGC Container Registry
- Running MXNet
For those unable to use the MXNet NGC container, to set up the required environment or create your own container, see the versioned NVIDIA Container Support Matrix.
Quick Start Guide
To train your model using mixed or TF32 precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the ResNet-50 model on the ImageNet 1k dataset. For the specifics concerning training and inference, see the Advanced section.
Clone the repository.
git clone https://github.com/NVIDIA/DeepLearningExamples cd DeepLearningExamples/MxNet/Classification/RN50v1.5Build the ResNet-50 MXNet NGC container.
After Docker is set up, you can build the ResNet-50 image with:
docker build . -t nvidia_rn50_mx
Start an interactive session in the NGC container to run preprocessing/training/inference.
nvidia-docker run --rm -it --ipc=host -v <path to dataset>:/data/imagenet/train-val-recordio-passthrough nvidia_rn50_mxDownload the data.
- Download the images from
http://image-net.org/download-images. Extract the training and validation data:
mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done cd .. mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash
Preprocess the ImageNet 1k dataset.
./scripts/prepare_imagenet.sh <path to raw imagenet> <path where processed dataset will be created>Start training.
./runner -n <number of gpus> -b <batch size per GPU (default 192)>Start validation/evaluation.
./runner -n <number of gpus> -b <batch size per GPU (default 192)> --load <path to trained model> --mode valStart inference/predictions.
./runner --load <path to trained model> --mode pred --data-pred <path to the image>
Advanced
The following sections provide greater details of the dataset, running training and inference, and the training results.
Scripts and sample code
In the root directory, the most important files are:
runner: A wrapper on thetrain.pyscript which is the main executable script for training/validation/predicting.benchmark.py: A script for benchmarking.Dockerfile: Container to build the container.fit.py: A file containing most of the training and validation logic.data.py: Data loading and preprocessing code.dali.py: Data loading and preprocessing code using DALI.models.py: The model architecture.report.py: A file containing JSON report structure and description of fields.
In the scripts directory, the most important files are:
prepare_imagenet.sh: A script that converts raw dataset format to RecordIO format.
Parameters
The complete list of available parameters contains:
Model:
--arch {resnetv1,resnetv15,resnextv1,resnextv15,xception}
model architecture (default: resnetv15)
--num-layers NUM_LAYERS
number of layers in the neural network, required by
some networks such as resnet (default: 50)
--num-groups NUM_GROUPS
number of groups for grouped convolutions, required by
some networks such as resnext (default: 32)
--num-classes NUM_CLASSES
the number of classes (default: 1000)
--batchnorm-eps BATCHNORM_EPS
the amount added to the batchnorm variance to prevent
output explosion. (default: 1e-05)
--batchnorm-mom BATCHNORM_MOM
the leaky-integrator factor controling the batchnorm
mean and variance. (default: 0.9)
--fuse-bn-relu FUSE_BN_RELU
have batchnorm kernel perform activation relu
(default: 0)
--fuse-bn-add-relu FUSE_BN_ADD_RELU
have batchnorm kernel perform add followed by
activation relu (default: 0)
Training:
--mode {train_val,train,val,pred}
mode (default: train_val)
--seed SEED random seed (default: None)
--gpus GPUS list of gpus to run, e.g. 0 or 0,2,5 (default: [0])
--kv-store {device,horovod}
key-value store type (default: device)
--dtype {float32,float16}
precision (default: float16)
--amp If enabled, turn on AMP (Automatic Mixed Precision)
(default: False)
--batch-size BATCH_SIZE
the batch size (default: 192)
--num-epochs NUM_EPOCHS
number of epochs (default: 90)
--lr LR initial learning rate (default: 0.1)
--lr-schedule {multistep,cosine}
learning rate schedule (default: cosine)
--lr-factor LR_FACTOR
the ratio to reduce lr on each step (default: 0.256)
--lr-steps LR_STEPS the epochs to reduce the lr, e.g. 30,60 (default: [])
--warmup-epochs WARMUP_EPOCHS
the epochs to ramp-up lr to scaled large-batch value
(default: 5)
--optimizer OPTIMIZER
the optimizer type (default: sgd)
--mom MOM momentum for sgd (default: 0.875)
--wd WD weight decay for sgd (default: 3.0517578125e-05)
--label-smoothing LABEL_SMOOTHING
label smoothing factor (default: 0.1)
--mixup MIXUP alpha parameter for mixup (if 0 then mixup is not
applied) (default: 0)
--disp-batches DISP_BATCHES
show progress for every n batches (default: 20)
--model-prefix MODEL_PREFIX
model checkpoint prefix (default: model)
--save-frequency SAVE_FREQUENCY
frequency of saving model in epochs (--model-prefix
must be specified). If -1 then save only best model.
If 0 then do not save anything. (default: -1)
--begin-epoch BEGIN_EPOCH
start the model from an epoch (default: 0)
--load LOAD checkpoint to load (default: None)
--test-io test reading speed without training (default: False)
--test-io-mode {train,val}
data to test (default: train)
--log LOG file where to save the log from the experiment
(default: log.log)
--dllogger-log DLLOGGER_LOG
file where to save the dllogger log from the
experiment (default: dllogger_log.log)
--workspace WORKSPACE
path to directory where results will be stored
(default: ./)
--no-metrics do not calculate evaluation metrics (for benchmarking)
(default: False)
--benchmark-iters BENCHMARK_ITERS
run only benchmark-iters iterations from each epoch
(default: None)
Data:
--data-train DATA_TRAIN
the training data (default: None)
--data-train-idx DATA_TRAIN_IDX
the index of training data (default: )
--data-val DATA_VAL the validation data (default: None)
--data-val-idx DATA_VAL_IDX
the index of validation data (default: )
--data-pred DATA_PRED
the image on which run inference (only for pred mode)
(default: None)
--data-backend {dali-gpu,dali-cpu,mxnet,synthetic}
set data loading & augmentation backend (default:
dali-gpu)
--image-shape IMAGE_SHAPE
the image shape feed into the network (default: [3,
224, 224])
--rgb-mean RGB_MEAN a tuple of size 3 for the mean rgb (default: [123.68,
116.779, 103.939])
--rgb-std RGB_STD a tuple of size 3 for the std rgb (default: [58.393,
57.12, 57.375])
--input-layout {NCHW,NHWC}
the layout of the input data (default: NCHW)
--conv-layout {NCHW,NHWC}
the layout of the data assumed by the conv operation
(default: NCHW)
--batchnorm-layout {NCHW,NHWC}
the layout of the data assumed by the batchnorm
operation (default: NCHW)
--pooling-layout {NCHW,NHWC}
the layout of the data assumed by the pooling
operation (default: NCHW)
--num-examples NUM_EXAMPLES
the number of training examples (doesn't work with
mxnet data backend) (default: 1281167)
--data-val-resize DATA_VAL_RESIZE
base length of shorter edge for validation dataset
(default: 256)
DALI data backend:
entire group applies only to dali data backend
--dali-separ-val each process will perform independent validation on
whole val-set (default: False)
--dali-threads DALI_THREADS
number of threadsper GPU for DALI (default: 3)
--dali-validation-threads DALI_VALIDATION_THREADS
number of threadsper GPU for DALI for validation
(default: 10)
--dali-prefetch-queue DALI_PREFETCH_QUEUE
DALI prefetch queue depth (default: 2)
--dali-nvjpeg-memory-padding DALI_NVJPEG_MEMORY_PADDING
Memory padding value for nvJPEG (in MB) (default: 64)
--dali-fuse-decoder DALI_FUSE_DECODER
0 or 1 whether to fuse decoder or not (default: 1)
MXNet data backend:
entire group applies only to mxnet data backend
--data-mxnet-threads DATA_MXNET_THREADS
number of threads for data decoding for mxnet data
backend (default: 40)
--random-crop RANDOM_CROP
if or not randomly crop the image (default: 0)
--random-mirror RANDOM_MIRROR
if or not randomly flip horizontally (default: 1)
--max-random-h MAX_RANDOM_H
max change of hue, whose range is [0, 180] (default:
0)
--max-random-s MAX_RANDOM_S
max change of saturation, whose range is [0, 255]
(default: 0)
--max-random-l MAX_RANDOM_L
max change of intensity, whose range is [0, 255]
(default: 0)
--min-random-aspect-ratio MIN_RANDOM_ASPECT_RATIO
min value of aspect ratio, whose value is either None
or a positive value. (default: 0.75)
--max-random-aspect-ratio MAX_RANDOM_ASPECT_RATIO
max value of aspect ratio. If min_random_aspect_ratio
is None, the aspect ratio range is
[1-max_random_aspect_ratio,
1+max_random_aspect_ratio], otherwise it is
[min_random_aspect_ratio, max_random_aspect_ratio].
(default: 1.33)
--max-random-rotate-angle MAX_RANDOM_ROTATE_ANGLE
max angle to rotate, whose range is [0, 360] (default:
0)
--max-random-shear-ratio MAX_RANDOM_SHEAR_RATIO
max ratio to shear, whose range is [0, 1] (default: 0)
--max-random-scale MAX_RANDOM_SCALE
max ratio to scale (default: 1)
--min-random-scale MIN_RANDOM_SCALE
min ratio to scale, should >= img_size/input_shape.
otherwise use --pad-size (default: 1)
--max-random-area MAX_RANDOM_AREA
max area to crop in random resized crop, whose range
is [0, 1] (default: 1)
--min-random-area MIN_RANDOM_AREA
min area to crop in random resized crop, whose range
is [0, 1] (default: 0.05)
--min-crop-size MIN_CROP_SIZE
Crop both width and height into a random size in
[min_crop_size, max_crop_size] (default: -1)
--max-crop-size MAX_CROP_SIZE
Crop both width and height into a random size in
[min_crop_size, max_crop_size] (default: -1)
--brightness BRIGHTNESS
brightness jittering, whose range is [0, 1] (default:
0)
--contrast CONTRAST contrast jittering, whose range is [0, 1] (default: 0)
--saturation SATURATION
saturation jittering, whose range is [0, 1] (default:
0)
--pca-noise PCA_NOISE
pca noise, whose range is [0, 1] (default: 0)
--random-resized-crop RANDOM_RESIZED_CROP
whether to use random resized crop (default: 1)
Command-line options
To see the full list of available options and their descriptions, use the -h or --help command line option:
./runner --help and python train.py --help
./runner acts as a wrapper on train.py and all additional flags will be passed to train.py.
Getting the data
The MXNet ResNet-50 v1.5 script operates on ImageNet 1k, a widely popular image classification dataset from ILSVRC challenge. You can download the images from http://image-net.org/download-images.
The recommended data format is
RecordIO, which
concatenates multiple examples into seekable binary files for better read
efficiency. MXNet provides a tool called im2rec.py located in the /opt/mxnet/tools/ directory.
The tool converts individual images into .rec files.
To prepare a RecordIO file containing ImageNet data, we first need to create .lst files
which consist of the labels and image paths. We assume that the original images were
downloaded to /data/imagenet/raw/train-jpeg and /data/imagenet/raw/val-jpeg.
python /opt/mxnet/tools/im2rec.py --list --recursive train /data/imagenet/raw/train-jpeg
python /opt/mxnet/tools/im2rec.py --list --recursive val /data/imagenet/raw/val-jpeg
Next, we generate the .rec (RecordIO files with data) and .idx (indexes required by DALI
to speed up data loading) files. To obtain the best training accuracy we do not preprocess the images when creating the RecordIO file.
python /opt/mxnet/tools/im2rec.py --pass-through --num-thread 40 train /data/imagenet/raw/train-jpeg
python /opt/mxnet/tools/im2rec.py --pass-through --num-thread 40 val /data/imagenet/raw/val-jpeg
Dataset guidelines
The process of loading, normalizing, and augmenting the data contained in the dataset can be found in the data.py and dali.py files.
The data is read from RecordIO format, which concatenates multiple examples into seekable binary files for better read efficiency.
Data augmentation techniques are described in the Default configuration section.
Multi-dataset
In most cases, to train a model on a different dataset, no changes in the code are required, but the dataset has to be converted into RecordIO format.
To convert a custom dataset, follow the steps from Getting the data section, and refer to the scripts/prepare_dataset.py script.
Training process
To start training, run:
./runner -n <number of gpus> -b <batch size per GPU> --data-root <path to imagenet> --dtype <float32 or float16>
By default, the training script runs the validation after each epoch:
- The best checkpoint will be stored in the
model_best.paramsfile in the working directory. - The log from training will be saved in the
log.logfile in the working directory. - The JSON report with statistics will be saved in the
report.jsonfile in the working directory.
If ImageNet is mounted in the /data/imagenet/train-val-recordio-passthrough directory, you don't have to specify the --data-root flag.
Inference process
To start validation, run:
./runner -n <number of gpus> -b <batch size per GPU> --data-root <path to imagenet> --dtype <float32 or float16> --mode val
By default:
- The log from validation will be saved in the
log.logfile in the working directory. - The JSON report with statistics will be saved in the
report.jsonfile in the working directory.
Performance
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA’s latest software release. For the most up-to-date performance measurements, go to NVIDIA Data Center Deep Learning Product Performance.
Benchmarking
To benchmark training and inference, run:
python benchmark.py -n <numbers of gpus separated by comma> -b <batch sizes per GPU separated by comma> --data-root <path to imagenet> --dtype <float32 or float16> -o <path to benchmark report>
- To control the benchmark length per epoch, use the
-iflag (defaults to 100 iterations). - To control the number of epochs, use the
-eflag. - To control the number of warmup epochs (epochs which are not taken into account), use the
-wflag. - To limit the length of the dataset, use the
--num-examplesflag.
By default, the same parameters as in ./runner will be used. Additional flags will be passed to ./runner.
Training performance benchmark
To benchmark only training, use the --mode train flag.
Inference performance benchmark
To benchmark only inference, use the --mode val flag.
Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
Training accuracy results
Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
90 epochs configuration
Our results were obtained by running 8 times the ./runner -n <number of gpus> -b 512 --dtype float32 script for TF32 and the ./runner -n <number of gpus> -b 512 script for mixed precision in the mxnet-22.10-py3 NGC container on NVIDIA DGX A100 with (8x A100 80GB) GPUs.
| GPUs | Accuracy - mixed precision | Accuracy - TF32 | Time to train - mixed precision | Time to train - TF32 | Time to train - speedup |
|---|---|---|---|---|---|
| 1 | 77.185 | 77.184 | 8.75 | 29.39 | 3.36 |
| 8 | 77.185 | 77.184 | 1.14 | 3.82 | 3.35 |
Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
90 epochs configuration
Our results were obtained by running the ./runner -n <number of gpus> -b 96 --dtype float32 training script for FP32 and the ./runner -n <number of gpus> -b 192 training script for mixed precision in the mxnet-22.10-py3 NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs.
| GPUs | Accuracy - mixed precision | Accuracy - FP32 | Time to train - mixed precision | Time to train - FP32 | Time to train - speedup |
|---|---|---|---|---|---|
| 1 | 77.342 | 77.160 | 24.2 | 84.5 | 3.49 |
| 4 | 77.196 | 77.290 | 6.0 | 21.4 | 3.59 |
| 8 | 77.150 | 77.313 | 3.0 | 10.7 | 3.54 |
Training stability test
Our results were obtained by running the following commands 8 times with different seeds.
For 50 epochs
./runner -n 8 -b 96 --dtype float32 --num-epochs 50for FP32./runner -n 8 -b 192 --num-epochs 50for mixed precision
For 90 epochs
./runner -n 8 -b 96 --dtype float32for FP32./runner -n 8 -b 192for mixed precision
For 250 epochs
./runner -n 8 -b 96 --dtype float32 --num-epochs 250 --mixup 0.2for FP32./runner -n 8 -b 192 --num-epochs 250 --mixup 0.2for mixed precision
| # of epochs | mixed precision avg top1 | FP32 avg top1 | mixed precision standard deviation | FP32 standard deviation | mixed precision minimum top1 | FP32 minimum top1 | mixed precision maximum top1 | FP32 maximum top1 |
|---|---|---|---|---|---|---|---|---|
| 50 | 76.308 | 76.329 | 0.00073 | 0.00094 | 76.230 | 76.234 | 76.440 | 76.470 |
| 90 | 77.150 | 77.313 | 0.00098 | 0.00085 | 76.972 | 77.228 | 77.266 | 77.474 |
| 250 | 78.460 | 78.483 | 0.00078 | 0.00065 | 78.284 | 78.404 | 78.560 | 78.598 |
Plots for 250 epoch configuration Here are example graphs of FP32 and mixed precision training on 8 GPU 250 epochs configuration:



Training performance results
Training performance: NVIDIA DGX A100 (8x A100 80GB)
The following results were obtained by running the
python benchmark.py -n 1,4,8 -b 512 --dtype float32 -o benchmark_report_tf32.json -i 500 -e 3 -w 1 --num-examples 32000 --mode train script for TF32 and the
python benchmark.py -n 1,4,8 -b 512 --dtype float16 -o benchmark_report_fp16.json -i 500 -e 3 -w 1 --num-examples 32000 --mode train script for mixed precision in the mxnet-22.10-py3 NGC container on NVIDIA DGX A100 with (8x A100 80GB) GPUs.
Training performance reported as Total IPS (data + compute time taken into account). Weak scaling is calculated as a ratio of speed for given number of GPUs to speed for 1 GPU.
| GPUs | Throughput - mixed precision | Throughput - TF32 | Throughput speedup (TF32 - mixed precision) | Weak scaling - mixed precision | Weak scaling - TF32 |
|---|---|---|---|---|---|
| 1 | 3410.52 | 1055.78 | 2.18 | 1.00 | 1.00 |
| 4 | 13442.66 | 4182.30 | 3.24 | 3.97 | 3.96 |
| 8 | 26673.72 | 8247.44 | 3.23 | 7.82 | 7.81 |
Training performance: NVIDIA DGX-1 (8x V100 16GB)
The following results were obtained by running the
python benchmark.py -n 1,2,4,8 -b 192 --dtype float16 -o benchmark_report_fp16.json -i 500 -e 3 -w 1 --num-examples 32000 --mode train script for mixed precision and the
python benchmark.py -n 1,2,4,8 -b 96 --dtype float32 -o benchmark_report_fp32.json -i 500 -e 3 -w 1 --num-examples 32000 --mode train script for FP32 in the mxnet-20.12-py3 NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs.
Training performance reported as Total IPS (data + compute time taken into account). Weak scaling is calculated as a ratio of speed for given number of GPUs to speed for 1 GPU.
| GPUs | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 - mixed precision) | Weak scaling - mixed precision | Weak scaling - FP32 |
|---|---|---|---|---|---|
| 1 | 1376 | 384 | 3.58 | 1.00 | 1.00 |
| 2 | 2768 | 763 | 3.62 | 2.01 | 1.98 |
| 4 | 5357 | 1513 | 3.54 | 3.89 | 3.94 |
| 8 | 10723 | 3005 | 3.56 | 7.79 | 7.82 |
Training performance: NVIDIA DGX-2 (16x V100 32GB)
The following results were obtained by running the
python benchmark.py -n 1,2,4,8,16 -b 256 --dtype float16 -o benchmark_report_fp16.json -i 500 -e 3 -w 1 --num-examples 32000 --mode train script for mixed precision and the
python benchmark.py -n 1,2,4,8,16 -b 128 --dtype float32 -o benchmark_report_fp32.json -i 500 -e 3 -w 1 --num-examples 32000 --mode train script for FP32 in the mxnet-20.12-py3 NGC container on NVIDIA DGX-2 with (16x V100 32GB) GPUs.
Training performance reported as Total IPS (data + compute time taken into account). Weak scaling is calculated as a ratio of speed for given number of GPUs to speed for 1 GPU.
| GPUs | Throughput - mixed precision | Throughput - FP32 | Throughput speedup (FP32 - mixed precision) | Weak scaling - mixed precision | Weak scaling - FP32 |
|---|---|---|---|---|---|
| 1 | 1492 | 417 | 3.57 | 1.00 | 1.00 |
| 2 | 2935 | 821 | 3.57 | 1.96 | 1.96 |
| 4 | 5726 | 1623 | 3.52 | 3.83 | 3.92 |
| 8 | 11368 | 3223 | 3.52 | 7.61 | 7.72 |
| 16 | 21484 | 6338 | 3.38 | 14.39 | 15.19 |
Inference performance results
Inference performance: NVIDIA DGX A100 (1x A100 80GB)
The following results were obtained by running the
python benchmark.py -n 1 -b 1,2,4,8,16,32,64,128,192,256 --dtype float16 -o inferbenchmark_report_fp16.json -i 500 -e 3 -w 1 --mode val script for mixed precision and the
python benchmark.py -n 1 -b 1,2,4,8,16,32,64,128,192,256 --dtype float32 -o inferbenchmark_report_tf32.json -i 500 -e 3 -w 1 --mode val script for TF32 in the mxnet-22.10-py3 NGC container on NVIDIA DGX A100 with (8x A100 80GB) GPUs.
Inference performance reported as Total IPS (data + compute time taken into account). Reported mixed precision speedups are relative to TF32 numbers for corresponding configuration.
| Batch size | Throughput (img/sec) - mixed precision | Throughput - speedup | Avg latency (ms) - mixed precision | Avg latency - speedup | 50% latency (ms) - mixed precision | 50% latency - speedup | 90% latency (ms) - mixed precision | 90% latency - speedup | 95% latency (ms) - mixed precision | 95% latency - speedup | 99% latency (ms) - mixed precision | 99% latency - speedup |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1431.99 | 1.9 | 0.7 | 1.9 | 0.68 | 1.95 | 0.71 | 1.9 | 0.84 | 1.65 | 0.88 | 1.7 |
| 2 | 2530.66 | 2.19 | 0.79 | 2.19 | 0.74 | 2.31 | 0.86 | 2.05 | 0.93 | 2.0 | 2.0 | |
| 4 | 3680.74 | 2.11 | 1.09 | 2.11 | 0.92 | 2.49 | 1.21 | 1.98 | 1.64 | 1.51 | 6.03 | |
| 8 | 2593.88 | 1.11 | 3.08 | 1.11 | 2.89 | 1.17 | 4.09 | 0.89 | 4.72 | 0.8 | 9.85 | |
| 16 | 4340.08 | 1.52 | 3.69 | 1.52 | 3.31 | 1.68 | 4.73 | 1.24 | 6.3 | 0.95 | 12.31 | |
| 32 | 6808.22 | 2.1 | 4.7 | 2.1 | 4.0 | 2.46 | 6.44 | 1.58 | 9.01 | 1.15 | 15.88 | |
| 64 | 7659.96 | 2.21 | 8.36 | 2.21 | 7.44 | 2.48 | 10.76 | 1.75 | 13.91 | 1.37 | 21.96 | |
| 128 | 8017.67 | 2.23 | 15.96 | 2.23 | 15.0 | 2.37 | 18.95 | 1.9 | 21.65 | 1.67 | 30.36 | |
| 192 | 8240.8 | 2.26 | 23.3 | 2.26 | 22.49 | 2.33 | 25.65 | 2.07 | 27.54 | 1.94 | 37.19 | |
| 256 | 7909.62 | 2.15 | 32.37 | 2.15 | 31.66 | 2.2 | 34.27 | 2.05 | 37.02 | 1.9 | 42.83 | |
| 512 | 7213.43 | 2.07 | 70.98 | 2.07 | 70.48 | 2.08 | 73.21 | 2.04 | 74.38 | 2.03 | 79.15 |
Inference performance: NVIDIA DGX-1 (1x V100 16GB)
The following results were obtained by running the
python benchmark.py -n 1 -b 1,2,4,8,16,32,64,128,192,256 --dtype float16 -o inferbenchmark_report_fp16.json -i 500 -e 3 -w 1 --mode val script for mixed precision and the
python benchmark.py -n 1 -b 1,2,4,8,16,32,64,128,192,256 --dtype float32 -o inferbenchmark_report_fp32.json -i 500 -e 3 -w 1 --mode val script for FP32 in the mxnet-20.12-py3 NGC container on NVIDIA DGX-1 with (8x V100 16GB) GPUs.
Inference performance reported as Total IPS (data + compute time taken into account). Reported mixed precision speedups are relative to FP32 numbers for corresponding configuration.
| Batch size | Throughput (img/sec) - mixed precision | Throughput - speedup | Avg latency (ms) - mixed precision | Avg latency - speedup | 50% latency (ms) - mixed precision | 50% latency - speedup | 90% latency (ms) - mixed precision | 90% latency - speedup | 95% latency (ms) - mixed precision | 95% latency - speedup | 99% latency (ms) - mixed precision | 99% latency - speedup | |:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:| | 1 | 286 | 1.27 | 3.48 | 1.27 | 3.45 | 1.27 | 3.61 | 1.26| 3.68 | 1.26| 3.86 | 1.24| | 2 | 519 | 1.34 | 3.84 | 1.34 | 3.77 | 1.35 | 4.05 | 1.31| 4.16 | 1.29| 4.59 | 1.27| | 4 | 910 | 1.60 | 4.39 | 1.60 | 4.35 | 1.61 | 4.59 | 1.56| 4.66 | 1.56| 5.19 | 1.47| | 8 | 1642| 2.20 | 4.87 | 2.20 | 4.68 | 2.29 | 5.35 | 2.05| 6.01 | 1.84| 11.06| 1.04| | 16 | 2359| 2.55 | 6.78 | 2.55 | 6.49 | 2.66 | 7.07 | 2.48| 8.33 | 2.12| 13.89| 1.30| | 32 | 2902| 2.86 | 11.02| 2.86 | 10.43| 3.02 | 12.25| 2.60| 13.88| 2.31| 21.41| 1.55| | 64 | 3234| 2.74 | 19.78| 2.74 | 18.89| 2.86 | 22.50| 2.44| 25.38| 2.17| 30.78| 1.81| | 128 | 3362| 2.69 | 38.06| 2.69 | 37.20| 2.75 | 42.32| 2.44| 45.12| 2.30| 50.59| 2.07| | 192 | 3178| 2.52 | 60.40| 2.52 | 59.62| 2.55 | 65.56| 2.35| 68.16| 2.25| 73.72| 2.10| | 256 | 3057| 2.38 | 83.73| 2.38 | 82.77| 2.40 | 92.26| 2.24| 92.26| 2.17|100.84| 2.23|
Inference performance: NVIDIA T4
The following results were obtained by running the
python benchmark.py -n 1 -b 1,2,4,8,16,32,64,128,192,256 --dtype float16 -o inferbenchmark_report_fp16.json -i 500 -e 3 -w 1 --mode val script for mixed precision and the
python benchmark.py -n 1 -b 1,2,4,8,16,32,64,128,192,256 --dtype float32 -o inferbenchmark_report_fp32.json -i 500 -e 3 -w 1 --mode val script for FP32 in the mxnet-20.12-py3 NGC container on an NVIDIA T4 GPU.
Inference performance reported as Total IPS (data + compute time taken into account). Reported mixed precision speedups are relative to FP32 numbers for corresponding configuration.
| Batch size | Throughput (img/sec) - mixed precision | Throughput - speedup | Avg latency (ms) - mixed precision | Avg latency - speedup | 50% latency (ms) - mixed precision | 50% latency - speedup | 90% latency (ms) - mixed precision | 90% latency - speedup | 95% latency (ms) - mixed precision | 95% latency - speedup | 99% latency (ms) - mixed precision | 99% latency - speedup |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 131 | 1.11 | 7.61 | 1.17 | 7.10 | 0.97 | 10.28 | 0.92 | 11.35 | 0.95 | 15.05 | 0.96 |
| 2 | 277 | 1.48 | 7.20 | 1.53 | 7.30 | 1.19 | 7.74 | 1.48 | 8.82 | 1.49 | 12.09 | 1.58 |
| 4 | 374 | 1.47 | 10.67 | 1.50 | 10.20 | 1.40 | 13.51 | 1.09 | 14.82 | 1.03 | 22.36 | 0.74 |
| 8 | 672 | 2.21 | 11.90 | 2.23 | 11.21 | 2.21 | 14.54 | 1.74 | 17.24 | 1.48 | 28.65 | 0.92 |
| 16 | 1267 | 3.57 | 12.62 | 3.58 | 12.02 | 3.59 | 14.02 | 3.13 | 16.02 | 2.76 | 22.28 | 2.01 |
| 32 | 1473 | 3.85 | 21.71 | 3.86 | 21.67 | 3.76 | 22.63 | 3.64 | 22.98 | 3.60 | 23.85 | 3.52 |
| 64 | 1561 | 3.70 | 40.98 | 3.70 | 40.87 | 3.64 | 41.98 | 3.57 | 42.56 | 3.53 | 43.85 | 3.46 |
| 128 | 1555 | 3.60 | 82.26 | 3.60 | 81.86 | 3.57 | 83.87 | 3.51 | 84.63 | 3.49 | 96.56 | 3.09 |
| 192 | 1545 | 3.64 | 124.26 | 3.64 | 123.67 | 3.61 | 125.76 | 3.58 | 126.73 | 3.56 | 143.27 | 3.19 |
| 256 | 1559 | 3.71 | 164.15 | 3.71 | 163.97 | 3.71 | 166.28 | 3.70 | 167.01 | 3.70 | 168.54 | 3.69 |
Release notes
Changelog
- Dec, 2018
- Initial release (based on https://github.com/apache/incubator-mxnet/tree/v1.8.x/example/image-classification)
- June, 2019
- Code refactor
- Label smoothing
- Cosine LR schedule
- MixUp regularization
- Better configurations
- February, 2021
- DGX-A100 performance results
- Container version upgraded to 20.12
- December, 2022
- Container version upgraded to 22.10
- Updated the A100 performance results. V100 and T4 performance results reflect the performance using the 20.12 container
Known Issues
There are no known issues with this model.