|
|
@@ -4,17 +4,18 @@ This repository provides a script and recipe to train Tacotron 2 and WaveGlow
|
|
|
v1.6 models to achieve state of the art accuracy, and is tested and maintained by NVIDIA.
|
|
|
|
|
|
## Table of Contents
|
|
|
-* [Model overview](#model-overview)
|
|
|
+- [Model overview](#model-overview)
|
|
|
* [Model architecture](#model-architecture)
|
|
|
* [Default configuration](#default-configuration)
|
|
|
* [Feature support matrix](#feature-support-matrix)
|
|
|
* [Features](#features)
|
|
|
* [Mixed precision training](#mixed-precision-training)
|
|
|
* [Enabling mixed precision](#enabling-mixed-precision)
|
|
|
-* [Setup](#setup)
|
|
|
+ * [Enabling TF32](#enabling-tf32)
|
|
|
+- [Setup](#setup)
|
|
|
* [Requirements](#requirements)
|
|
|
-* [Quick Start Guide](#quick-start-guide)
|
|
|
-* [Advanced](#advanced)
|
|
|
+- [Quick Start Guide](#quick-start-guide)
|
|
|
+- [Advanced](#advanced)
|
|
|
* [Scripts and sample code](#scripts-and-sample-code)
|
|
|
* [Parameters](#parameters)
|
|
|
* [Shared parameters](#shared-parameters)
|
|
|
@@ -27,20 +28,24 @@ v1.6 models to achieve state of the art accuracy, and is tested and maintained b
|
|
|
* [Multi-dataset](#multi-dataset)
|
|
|
* [Training process](#training-process)
|
|
|
* [Inference process](#inference-process)
|
|
|
-* [Performance](#performance)
|
|
|
+- [Performance](#performance)
|
|
|
* [Benchmarking](#benchmarking)
|
|
|
* [Training performance benchmark](#training-performance-benchmark)
|
|
|
* [Inference performance benchmark](#inference-performance-benchmark)
|
|
|
* [Results](#results)
|
|
|
* [Training accuracy results](#training-accuracy-results)
|
|
|
- * [Training accuracy: NVIDIA DGX-1 (8x V100 16G)](#training-accuracy-nvidia-dgx-1-8x-v100-16g)
|
|
|
+ * [Training accuracy: NVIDIA DGX A100 (8x A100 40GB)](#training-accuracy-nvidia-dgx-a100-8x-a100-40gb)
|
|
|
+ * [Training accuracy: NVIDIA DGX-1 (8x V100 16GB)](#training-accuracy-nvidia-dgx-1-8x-v100-16gb)
|
|
|
+ * [Training curves](#training-curves)
|
|
|
* [Training performance results](#training-performance-results)
|
|
|
- * [Training performance: NVIDIA DGX-1 (8x V100 16G)](#training-performance-nvidia-dgx-1-8x-v100-16g)
|
|
|
+ * [Training performance: NVIDIA DGX A100 (8x A100 40GB)](#training-performance-nvidia-dgx-a100-8x-a100-40gb)
|
|
|
+ * [Training performance: NVIDIA DGX-1 (8x V100 16GB)](#training-performance-nvidia-dgx-1-8x-v100-16gB)
|
|
|
* [Expected training time](#expected-training-time)
|
|
|
* [Inference performance results](#inference-performance-results)
|
|
|
- * [Inference performance: NVIDIA V100 16G](#inference-performance-nvidia-v100-16g)
|
|
|
+ * [Inference performance: NVIDIA DGX A100 (1x A100 40GB)](#inference-performance-nvidia-dgx-a100-1x-a100-40gb)
|
|
|
+ * [Inference performance: NVIDIA DGX-1 (1x V100 16GB)](#inference-performance-nvidia-dgx-1-1x-v100-16gb)
|
|
|
* [Inference performance: NVIDIA T4](#inference-performance-nvidia-t4)
|
|
|
-* [Release notes](#release-notes)
|
|
|
+- [Release notes](#release-notes)
|
|
|
* [Changelog](#changelog)
|
|
|
* [Known issues](#known-issues)
|
|
|
|
|
|
@@ -71,12 +76,12 @@ available [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/).
|
|
|
The Tacotron 2 and WaveGlow model enables you to efficiently synthesize high
|
|
|
quality speech from text.
|
|
|
|
|
|
-Both models are trained with mixed precision using Tensor Cores on NVIDIA
|
|
|
-Volta and Turing GPUs. Therefore, researchers can get results 1.5x faster for Tacotron 2
|
|
|
-and 2.2x faster for WaveGlow than training without Tensor Cores, while
|
|
|
-experiencing the benefits of mixed precision training. The models are tested
|
|
|
-against each NGC monthly container release to ensure consistent accuracy and
|
|
|
-performance over time.
|
|
|
+Both models are trained with mixed precision using Tensor Cores on Volta,
|
|
|
+Turing, and the NVIDIA Ampere GPU architectures. Therefore, researchers can
|
|
|
+get results 2.0x faster for Tacotron 2 and 3.1x faster for WaveGlow than
|
|
|
+training without Tensor Cores, while experiencing the benefits of mixed
|
|
|
+precision training. The models are tested against each NGC monthly
|
|
|
+container release to ensure consistent accuracy and performance over time.
|
|
|
|
|
|
### Model architecture
|
|
|
|
|
|
@@ -143,7 +148,7 @@ performance by overlapping communication with computation during `backward()`
|
|
|
and bucketing smaller gradient transfers to reduce the total number of transfers
|
|
|
required.
|
|
|
|
|
|
-## Mixed precision training
|
|
|
+### Mixed precision training
|
|
|
|
|
|
*Mixed precision* is the combined use of different numerical precisions in a
|
|
|
computational method. [Mixed precision](https://arxiv.org/abs/1710.03740)
|
|
|
@@ -151,7 +156,8 @@ training offers significant computational speedup by performing operations in
|
|
|
half-precision format, while storing minimal information in single-precision
|
|
|
to retain as much information as possible in critical parts of the network.
|
|
|
Since the introduction of [Tensor Cores](https://developer.nvidia.com/tensor-cores)
|
|
|
-in the Volta and Turing architecture, significant training speedups are
|
|
|
+in Volta, and following with both the Turing and Ampere architectures,
|
|
|
+significant training speedups are
|
|
|
experienced by switching to mixed precision -- up to 3x overall speedup on
|
|
|
the most arithmetically intense model architectures. Using mixed precision
|
|
|
training requires two steps:
|
|
|
@@ -170,7 +176,7 @@ documentation.
|
|
|
blog.
|
|
|
* APEX tools for mixed precision training, see the [NVIDIA Apex: Tools for Easy Mixed-Precision Training in PyTorch](https://devblogs.nvidia.com/apex-pytorch-easy-mixed-precision-training/).
|
|
|
|
|
|
-### Enabling mixed precision
|
|
|
+#### Enabling mixed precision
|
|
|
|
|
|
Mixed precision is enabled in PyTorch by using the Automatic Mixed Precision
|
|
|
(AMP) library from [APEX](https://github.com/NVIDIA/apex) that casts variables
|
|
|
@@ -183,7 +189,7 @@ to be used can be [dynamic](https://nvidia.github.io/apex/fp16_utils.html#apex.f
|
|
|
|
|
|
By default, the `train_tacotron2.sh` and `train_waveglow.sh` scripts will
|
|
|
launch mixed precision training with Tensor Cores. You can change this
|
|
|
-behaviour by removing the `--amp-run` flag from the `train.py` script.
|
|
|
+behaviour by removing the `--amp` flag from the `train.py` script.
|
|
|
|
|
|
To enable mixed precision, the following steps were performed in the Tacotron 2 and
|
|
|
WaveGlow models:
|
|
|
@@ -219,6 +225,18 @@ called `losses`):
|
|
|
scaled_losses.backward()
|
|
|
```
|
|
|
|
|
|
+#### Enabling TF32
|
|
|
+
|
|
|
+TensorFloat-32 (TF32) is the new math mode in [NVIDIA A100](#https://www.nvidia.com/en-us/data-center/a100/) GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
|
|
|
+
|
|
|
+TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require high dynamic range for weights or activations.
|
|
|
+
|
|
|
+For more information, refer to the [TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x](#https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) blog post.
|
|
|
+
|
|
|
+TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
## Setup
|
|
|
|
|
|
The following section lists the requirements in order to start training the
|
|
|
@@ -230,18 +248,21 @@ This repository contains Dockerfile which extends the PyTorch NGC container
|
|
|
and encapsulates some dependencies. Aside from these dependencies, ensure you
|
|
|
have the following components:
|
|
|
|
|
|
-* [NVIDIA Docker](https://github.com/NVIDIA/nvidia-docker)
|
|
|
-* [PyTorch 20.03-py3+ NGC container](https://ngc.nvidia.com/registry/nvidia-pytorch)
|
|
|
+- [NVIDIA Docker](https://github.com/NVIDIA/nvidia-docker)
|
|
|
+- [PyTorch 20.06-py3 NGC container](https://ngc.nvidia.com/registry/nvidia-pytorch)
|
|
|
or newer
|
|
|
-* [NVIDIA Volta](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/) or [Turing](https://www.nvidia.com/en-us/geforce/turing/) based GPU
|
|
|
+- Supported GPUs:
|
|
|
+ - [NVIDIA Volta](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/)
|
|
|
+ - [NVIDIA Turing](https://www.nvidia.com/en-us/geforce/turing/)
|
|
|
+ - [NVIDIA Ampere architecture](https://www.nvidia.com/en-us/data-center/nvidia-ampere-gpu-architecture/)
|
|
|
|
|
|
For more information about how to get started with NGC containers, see the
|
|
|
following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning
|
|
|
Documentation:
|
|
|
|
|
|
-* [Getting Started Using NVIDIA GPU Cloud](https://docs.nvidia.com/ngc/ngc-getting-started-guide/index.html)
|
|
|
-* [Accessing And Pulling From The NGC Container Registry](https://docs.nvidia.com/deeplearning/frameworks/user-guide/index.html#accessing_registry)
|
|
|
-* [Running PyTorch](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/running.html#running)
|
|
|
+- [Getting Started Using NVIDIA GPU Cloud](https://docs.nvidia.com/ngc/ngc-getting-started-guide/index.html)
|
|
|
+- [Accessing And Pulling From The NGC Container Registry](https://docs.nvidia.com/deeplearning/frameworks/user-guide/index.html#accessing_registry)
|
|
|
+- [Running PyTorch](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/running.html#running)
|
|
|
|
|
|
For those unable to use the PyTorch NGC container, to set up the required
|
|
|
environment or create your own container, see the versioned
|
|
|
@@ -285,7 +306,7 @@ After you build the container image, you can start an interactive CLI session wi
|
|
|
```
|
|
|
|
|
|
The `interactive.sh` script requires that the location on the dataset is specified.
|
|
|
- For example, `LJSpeech-1.1`. To preprocess the datasets for Tacotron 2 training, use
|
|
|
+ For example, `LJSpeech-1.1`. To preprocess the datasets for Tacotron 2 training, use
|
|
|
the `./scripts/prepare_mels.sh` script:
|
|
|
```bash
|
|
|
bash scripts/prepare_mels.sh
|
|
|
@@ -323,27 +344,27 @@ inference using the respective checkpoints that are passed as `--tacotron2`
|
|
|
and `--waveglow` arguments. Tacotron2 and WaveGlow checkpoints can also be downloaded from NGC:
|
|
|
|
|
|
https://ngc.nvidia.com/catalog/models/nvidia:tacotron2pyt_fp16/files?version=3
|
|
|
-
|
|
|
+
|
|
|
https://ngc.nvidia.com/catalog/models/nvidia:waveglow256pyt_fp16/files?version=2
|
|
|
|
|
|
To run inference issue:
|
|
|
|
|
|
```bash
|
|
|
- python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 -o output/ -i phrases/phrase.txt --amp-run
|
|
|
+ python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 -o output/ -i phrases/phrase.txt --fp16
|
|
|
```
|
|
|
|
|
|
The speech is generated from lines of text in the file that is passed with
|
|
|
`-i` argument. The number of lines determines inference batch size. To run
|
|
|
- inference in mixed precision, use the `--amp-run` flag. The output audio will
|
|
|
+ inference in mixed precision, use the `--fp16` flag. The output audio will
|
|
|
be stored in the path specified by the `-o` argument.
|
|
|
|
|
|
- You can also run inference on CPU with TorchScript by adding flag --cpu-run:
|
|
|
+ You can also run inference on CPU with TorchScript by adding flag --cpu:
|
|
|
```bash
|
|
|
export CUDA_VISIBLE_DEVICES=
|
|
|
```
|
|
|
```bash
|
|
|
- python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 --cpu-run -o output/ -i phrases/phrase.txt
|
|
|
- ```
|
|
|
+ python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 --cpu -o output/ -i phrases/phrase.txt
|
|
|
+ ```
|
|
|
|
|
|
## Advanced
|
|
|
|
|
|
@@ -383,8 +404,8 @@ WaveGlow models.
|
|
|
* `--epochs` - number of epochs (Tacotron 2: 1501, WaveGlow: 1001)
|
|
|
* `--learning-rate` - learning rate (Tacotron 2: 1e-3, WaveGlow: 1e-4)
|
|
|
* `--batch-size` - batch size (Tacotron 2 FP16/FP32: 104/48, WaveGlow FP16/FP32: 10/4)
|
|
|
-* `--amp-run` - use mixed precision training
|
|
|
-* `--cpu-run` - use CPU with TorchScript for inference
|
|
|
+* `--amp` - use mixed precision training
|
|
|
+* `--cpu` - use CPU with TorchScript for inference
|
|
|
|
|
|
#### Shared audio/STFT parameters
|
|
|
|
|
|
@@ -482,24 +503,24 @@ models and input text as a text file, with one phrase per line.
|
|
|
|
|
|
To run inference, issue:
|
|
|
```bash
|
|
|
-python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 -o output/ --include-warmup -i phrases/phrase.txt --amp-run
|
|
|
+python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 -o output/ --include-warmup -i phrases/phrase.txt --fp16
|
|
|
```
|
|
|
Here, `Tacotron2_checkpoint` and `WaveGlow_checkpoint` are pre-trained
|
|
|
-checkpoints for the respective models, and `phrases/phrase.txt` contains input
|
|
|
-phrases. The number of text lines determines the inference batch size. Audio
|
|
|
+checkpoints for the respective models, and `phrases/phrase.txt` contains input
|
|
|
+phrases. The number of text lines determines the inference batch size. Audio
|
|
|
will be saved in the output folder. The audio files [audio_fp16](./audio/audio_fp16.wav)
|
|
|
-and [audio_fp32](./audio/audio_fp32.wav) were generated using checkpoints from
|
|
|
+and [audio_fp32](./audio/audio_fp32.wav) were generated using checkpoints from
|
|
|
mixed precision and FP32 training, respectively.
|
|
|
|
|
|
You can find all the available options by calling `python inference.py --help`.
|
|
|
|
|
|
-You can also run inference on CPU with TorchScript by adding flag --cpu-run:
|
|
|
+You can also run inference on CPU with TorchScript by adding flag --cpu:
|
|
|
```bash
|
|
|
export CUDA_VISIBLE_DEVICES=
|
|
|
```
|
|
|
```bash
|
|
|
-python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 --cpu-run -o output/ -i phrases/phrase.txt
|
|
|
-```
|
|
|
+python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> --wn-channels 256 --cpu -o output/ -i phrases/phrase.txt
|
|
|
+```
|
|
|
|
|
|
## Performance
|
|
|
|
|
|
@@ -517,9 +538,9 @@ To benchmark the training performance on a specific batch size, run:
|
|
|
* For 1 GPU
|
|
|
* FP16
|
|
|
```bash
|
|
|
- python train.py -m Tacotron2 -o <output_dir> -lr 1e-3 --epochs 10 -bs <batch_size> --weight-decay 1e-6 --grad-clip-thresh 1.0 --cudnn-enabled --log-file nvlog.json --load-mel-from-disk --training-files=filelists/ljs_mel_text_train_subset_2500_filelist.txt --validation-files=filelists/ljs_mel_text_val_filelist.txt --dataset-path <dataset-path> --amp-run
|
|
|
+ python train.py -m Tacotron2 -o <output_dir> -lr 1e-3 --epochs 10 -bs <batch_size> --weight-decay 1e-6 --grad-clip-thresh 1.0 --cudnn-enabled --log-file nvlog.json --load-mel-from-disk --training-files=filelists/ljs_mel_text_train_subset_2500_filelist.txt --validation-files=filelists/ljs_mel_text_val_filelist.txt --dataset-path <dataset-path> --amp
|
|
|
```
|
|
|
- * FP32
|
|
|
+ * TF32 (or FP32 if TF32 not enabled)
|
|
|
```bash
|
|
|
python train.py -m Tacotron2 -o <output_dir> -lr 1e-3 --epochs 10 -bs <batch_size> --weight-decay 1e-6 --grad-clip-thresh 1.0 --cudnn-enabled --log-file nvlog.json --load-mel-from-disk --training-files=filelists/ljs_mel_text_train_subset_2500_filelist.txt --validation-files=filelists/ljs_mel_text_val_filelist.txt --dataset-path <dataset-path>
|
|
|
```
|
|
|
@@ -527,9 +548,9 @@ To benchmark the training performance on a specific batch size, run:
|
|
|
* For multiple GPUs
|
|
|
* FP16
|
|
|
```bash
|
|
|
- python -m multiproc train.py -m Tacotron2 -o <output_dir> -lr 1e-3 --epochs 10 -bs <batch_size> --weight-decay 1e-6 --grad-clip-thresh 1.0 --cudnn-enabled --log-file nvlog.json --load-mel-from-disk --training-files=filelists/ljs_mel_text_train_subset_2500_filelist.txt --validation-files=filelists/ljs_mel_text_val_filelist.txt --dataset-path <dataset-path> --amp-run
|
|
|
+ python -m multiproc train.py -m Tacotron2 -o <output_dir> -lr 1e-3 --epochs 10 -bs <batch_size> --weight-decay 1e-6 --grad-clip-thresh 1.0 --cudnn-enabled --log-file nvlog.json --load-mel-from-disk --training-files=filelists/ljs_mel_text_train_subset_2500_filelist.txt --validation-files=filelists/ljs_mel_text_val_filelist.txt --dataset-path <dataset-path> --amp
|
|
|
```
|
|
|
- * FP32
|
|
|
+ * TF32 (or FP32 if TF32 not enabled)
|
|
|
```bash
|
|
|
python -m multiproc train.py -m Tacotron2 -o <output_dir> -lr 1e-3 --epochs 10 -bs <batch_size> --weight-decay 1e-6 --grad-clip-thresh 1.0 --cudnn-enabled --log-file nvlog.json --load-mel-from-disk --training-files=filelists/ljs_mel_text_train_subset_2500_filelist.txt --validation-files=filelists/ljs_mel_text_val_filelist.txt --dataset-path <dataset-path>
|
|
|
```
|
|
|
@@ -539,9 +560,9 @@ To benchmark the training performance on a specific batch size, run:
|
|
|
* For 1 GPU
|
|
|
* FP16
|
|
|
```bash
|
|
|
- python train.py -m WaveGlow -o <output_dir> -lr 1e-4 --epochs 10 -bs <batch_size> --segment-length 8000 --weight-decay 0 --grad-clip-thresh 65504.0 --cudnn-enabled --cudnn-benchmark --log-file nvlog.json --training-files filelists/ljs_audio_text_train_subset_1250_filelist.txt --dataset-path <dataset-path> --amp-run
|
|
|
+ python train.py -m WaveGlow -o <output_dir> -lr 1e-4 --epochs 10 -bs <batch_size> --segment-length 8000 --weight-decay 0 --grad-clip-thresh 65504.0 --cudnn-enabled --cudnn-benchmark --log-file nvlog.json --training-files filelists/ljs_audio_text_train_subset_1250_filelist.txt --dataset-path <dataset-path> --amp
|
|
|
```
|
|
|
- * FP32
|
|
|
+ * TF32 (or FP32 if TF32 not enabled)
|
|
|
```bash
|
|
|
python train.py -m WaveGlow -o <output_dir> -lr 1e-4 --epochs 10 -bs <batch_size> --segment-length 8000 --weight-decay 0 --grad-clip-thresh 3.4028234663852886e+38 --cudnn-enabled --cudnn-benchmark --log-file nvlog.json --training-files filelists/ljs_audio_text_train_subset_1250_filelist.txt --dataset-path <dataset-path>
|
|
|
```
|
|
|
@@ -549,9 +570,9 @@ To benchmark the training performance on a specific batch size, run:
|
|
|
* For multiple GPUs
|
|
|
* FP16
|
|
|
```bash
|
|
|
- python -m multiproc train.py -m WaveGlow -o <output_dir> -lr 1e-4 --epochs 10 -bs <batch_size> --segment-length 8000 --weight-decay 0 --grad-clip-thresh 65504.0 --cudnn-enabled --cudnn-benchmark --log-file nvlog.json --training-files filelists/ljs_audio_text_train_subset_1250_filelist.txt --dataset-path <dataset-path> --amp-run
|
|
|
+ python -m multiproc train.py -m WaveGlow -o <output_dir> -lr 1e-4 --epochs 10 -bs <batch_size> --segment-length 8000 --weight-decay 0 --grad-clip-thresh 65504.0 --cudnn-enabled --cudnn-benchmark --log-file nvlog.json --training-files filelists/ljs_audio_text_train_subset_1250_filelist.txt --dataset-path <dataset-path> --amp
|
|
|
```
|
|
|
- * FP32
|
|
|
+ * TF32 (or FP32 if TF32 not enabled)
|
|
|
```bash
|
|
|
python -m multiproc train.py -m WaveGlow -o <output_dir> -lr 1e-4 --epochs 10 -bs <batch_size> --segment-length 8000 --weight-decay 0 --grad-clip-thresh 3.4028234663852886e+38 --cudnn-enabled --cudnn-benchmark --log-file nvlog.json --training-files filelists/ljs_audio_text_train_subset_1250_filelist.txt --dataset-path <dataset-path>
|
|
|
```
|
|
|
@@ -566,9 +587,9 @@ To benchmark the inference performance on a batch size=1, run:
|
|
|
|
|
|
* For FP16
|
|
|
```bash
|
|
|
- python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> -o output/ --include-warmup -i phrases/phrase_1_64.txt --amp-run --log-file=output/nvlog_fp16.json
|
|
|
+ python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> -o output/ --include-warmup -i phrases/phrase_1_64.txt --fp16 --log-file=output/nvlog_fp16.json
|
|
|
```
|
|
|
-* For FP32
|
|
|
+* For TF32 (or FP32 if TF32 not enabled)
|
|
|
```bash
|
|
|
python inference.py --tacotron2 <Tacotron2_checkpoint> --waveglow <WaveGlow_checkpoint> -o output/ --include-warmup -i phrases/phrase_1_64.txt --log-file=output/nvlog_fp32.json
|
|
|
```
|
|
|
@@ -586,10 +607,43 @@ and accuracy in training and inference.
|
|
|
|
|
|
#### Training accuracy results
|
|
|
|
|
|
-##### Training accuracy: NVIDIA DGX-1 (8x V100 16G)
|
|
|
+##### Training accuracy: NVIDIA DGX A100 (8x A100 40GB)
|
|
|
+Our results were obtained by running the `./platform/DGXA100_{tacotron2,waveglow}_{AMP,TF32}_{1,4,8}NGPU_train.sh`
|
|
|
+training script in the PyTorch-20.06-py3 NGC container on
|
|
|
+NVIDIA DGX A100 (8x A100 40GB) GPUs.
|
|
|
+
|
|
|
+All of the results were produced using the `train.py` script as described in the
|
|
|
+[Training process](#training-process) section of this document. For each model,
|
|
|
+the loss is taken from a sample run.
|
|
|
+
|
|
|
+| Loss (Model/Epoch) | 1 | 250 | 500 | 750 | 1000 |
|
|
|
+| :----------------: | ------: | ------: | ------: | ------: | ------: |
|
|
|
+| Tacotron 2 FP16 | 3.82| 0.56| 0.42| 0.38| 0.35|
|
|
|
+| Tacotron 2 TF32 | 3.50| 0.54| 0.41| 0.37| 0.35|
|
|
|
+| WaveGlow FP16 | -3.31| -5.72| -5.87 | -5.94| -5.99
|
|
|
+| WaveGlow TF32 | -4.46| -5.93| -5.98| | |
|
|
|
|
|
|
-Our results were obtained by running the `./platform/train_{tacotron2,waveglow}_{AMP,FP32}_DGX1_16GB_8GPU.sh` training script in the PyTorch-19.06-py3
|
|
|
-NGC container on NVIDIA DGX-1 with 8x V100 16G GPUs.
|
|
|
+
|
|
|
+
|
|
|
+Figure 4. Tacotron 2 FP16 loss - batch size 128 (sample run)
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+Figure 5. Tacotron 2 TF32 loss - batch size 128 (sample run)
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+Figure 6. WaveGlow FP16 loss - batch size 10 (sample run)
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+Figure 7. WaveGlow TF32 loss - batch size 4 (sample run)
|
|
|
+
|
|
|
+##### Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
|
|
|
+
|
|
|
+Our results were obtained by running the `./platform/DGX1_{tacotron2,waveglow}_{AMP,TF32}_{1,4,8}NGPU_train.sh`
|
|
|
+training script in the PyTorch-20.06-py3 NGC container on
|
|
|
+NVIDIA DGX-1 with 8x V100 16G GPUs.
|
|
|
|
|
|
All of the results were produced using the `train.py` script as described in the
|
|
|
[Training process](#training-process) section of this document.
|
|
|
@@ -601,25 +655,78 @@ All of the results were produced using the `train.py` script as described in the
|
|
|
| WaveGlow FP16 | -2.2054 | -5.7602 | -5.901 | -5.9706 | -6.0258 |
|
|
|
| WaveGlow FP32 | -3.0327 | -5.858 | -6.0056 | -6.0613 | -6.1087 |
|
|
|
|
|
|
-Tacotron 2 FP16 loss - batch size 104 (mean and std over 16 runs)
|
|
|

|
|
|
|
|
|
-Tacotron 2 FP32 loss - batch size 48 (mean and std over 16 runs)
|
|
|
+Figure 4. Tacotron 2 FP16 loss - batch size 104 (mean and std over 16 runs)
|
|
|
+
|
|
|

|
|
|
|
|
|
-WaveGlow FP16 loss - batch size 10 (mean and std over 16 runs)
|
|
|
+Figure 5. Tacotron 2 FP32 loss - batch size 48 (mean and std over 16 runs)
|
|
|
+
|
|
|

|
|
|
|
|
|
-WaveGlow FP32 loss - batch size 4 (mean and std over 16 runs)
|
|
|
+Figure 6. WaveGlow FP16 loss - batch size 10 (mean and std over 16 runs)
|
|
|
+
|
|
|

|
|
|
|
|
|
+Figure 7. WaveGlow FP32 loss - batch size 4 (mean and std over 16 runs)
|
|
|
+
|
|
|
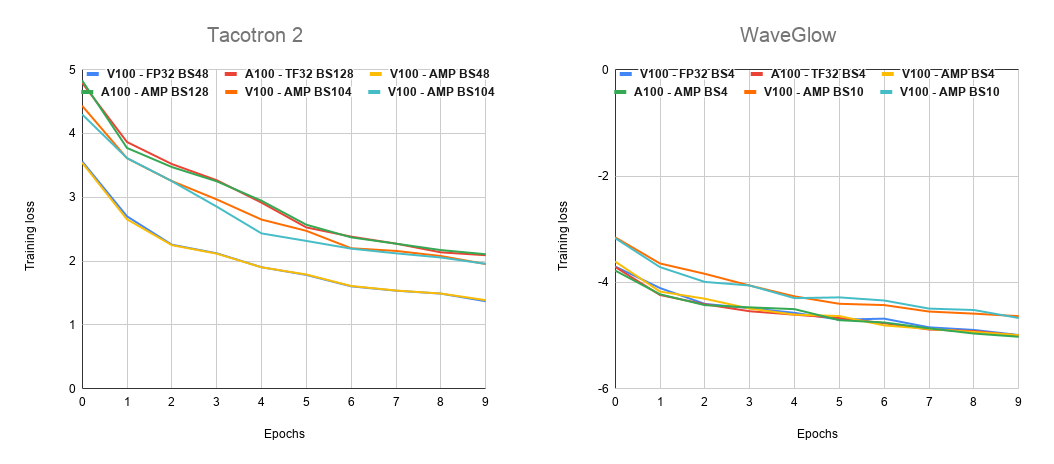
+#### Training curves
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+Figure 3. Tacotron 2 and WaveGlow training loss.
|
|
|
|
|
|
#### Training performance results
|
|
|
|
|
|
-##### Training performance: NVIDIA DGX-1 (8x V100 16G)
|
|
|
+##### Training performance: NVIDIA DGX A100 (8x A100 40GB)
|
|
|
+
|
|
|
+Our results were obtained by running the `./platform/DGXA100_{tacotron2,waveglow}_{AMP,TF32}_{1,4,8}NGPU_train.sh`
|
|
|
+training script in the [framework-container-name] NGC container on
|
|
|
+NVIDIA DGX A100 (8x A100 40GB) GPUs. Performance numbers (in output mel-spectrograms per second for
|
|
|
+Tacotron 2 and output samples per second for WaveGlow)
|
|
|
+were averaged over an entire training epoch.
|
|
|
+
|
|
|
+This table shows the results for Tacotron 2:
|
|
|
+
|
|
|
+|Number of GPUs|Batch size per GPU|Number of mels used with mixed precision|Number of mels used with TF32|Speed-up with mixed precision|Multi-GPU weak scaling with mixed precision|Multi-GPU weak scaling with TF32|
|
|
|
+|---:|---:|---:|---:|---:|---:|---:|
|
|
|
+|1| 128| 26,484| 31,499| 0.84| 1.00| 1.00|
|
|
|
+|4| 128| 107,482| 124,591| 0.86| 4.06| 3.96|
|
|
|
+|8| 128| 209,186| 250,556| 0.83| 7.90| 7.95|
|
|
|
+
|
|
|
+The following table shows the results for WaveGlow:
|
|
|
+
|
|
|
+|Number of GPUs|Batch size per GPU|Number of samples used with mixed precision|Number of samples used with TF32|Speed-up with mixed precision|Multi-GPU weak scaling with mixed precision|Multi-GPU weak scaling with TF32|
|
|
|
+|---:|---:|---:|---:|---:|---:|---:|
|
|
|
+|1| 10@FP16, 4@TF32 | 149,479| 67,581| 2.21| 1.00| 1.00|
|
|
|
+|4| 10@FP16, 4@TF32 | 532,363| 233,846| 2.28| 3.56| 3.46|
|
|
|
+|8| 10@FP16, 4@TF32 | 905,043| 383,043| 2.36| 6.05| 5.67|
|
|
|
+
|
|
|
+
|
|
|
+##### Expected training time
|
|
|
+
|
|
|
+The following table shows the expected training time for convergence for Tacotron 2 (1501 epochs):
|
|
|
|
|
|
-Our results were obtained by running the `./platform/train_{tacotron2,waveglow}_{AMP,FP32}_DGX1_16GB_8GPU.sh`
|
|
|
-training script in the PyTorch-19.12-py3 NGC container on NVIDIA DGX-1 with
|
|
|
+|Number of GPUs|Batch size per GPU|Time to train with mixed precision (Hrs)|Time to train with TF32 (Hrs)|Speed-up with mixed precision|
|
|
|
+|---:|---:|---:|---:|---:|
|
|
|
+|1| 128| 112| 94| 0.84|
|
|
|
+|4| 128| 29| 25| 0.87|
|
|
|
+|8| 128| 16| 14| 0.84|
|
|
|
+
|
|
|
+
|
|
|
+The following table shows the expected training time for convergence for WaveGlow (1001 epochs):
|
|
|
+
|
|
|
+|Number of GPUs|Batch size per GPU|Time to train with mixed precision (Hrs)|Time to train with TF32 (Hrs)|Speed-up with mixed precision|
|
|
|
+|---:|---:|---:|---:|---:|
|
|
|
+|1| 10@FP16, 4@TF32 | 188| 416| 2.21|
|
|
|
+|4| 10@FP16, 4@TF32 | 54| 122| 2.27|
|
|
|
+|8| 10@FP16, 4@TF32 | 33| 75| 2.29|
|
|
|
+
|
|
|
+##### Training performance: NVIDIA DGX-1 (8x V100 16GB)
|
|
|
+
|
|
|
+Our results were obtained by running the `./platform/DGX1_{tacotron2,waveglow}_{AMP,TF32}_{1,4,8}NGPU_train.sh`
|
|
|
+training script in the PyTorch-20.06-py3 NGC container on NVIDIA DGX-1 with
|
|
|
8x V100 16G GPUs. Performance numbers (in output mel-spectrograms per second for
|
|
|
Tacotron 2 and output samples per second for WaveGlow) were averaged over
|
|
|
an entire training epoch.
|
|
|
@@ -628,17 +735,17 @@ This table shows the results for Tacotron 2:
|
|
|
|
|
|
|Number of GPUs|Batch size per GPU|Number of mels used with mixed precision|Number of mels used with FP32|Speed-up with mixed precision|Multi-GPU weak scaling with mixed precision|Multi-GPU weak scaling with FP32|
|
|
|
|---:|---:|---:|---:|---:|---:|---:|
|
|
|
-|1|104@FP16, 48@FP32 | 15,313 | 9,674 | 1.58 | 1.00 | 1.00 |
|
|
|
-|4|104@FP16, 48@FP32 | 53,661 | 32,778 | 1.64 | 3.50 | 3.39 |
|
|
|
-|8|104@FP16, 48@FP32 | 100,422 | 59,549 | 1.69 | 6.56 | 6.16 |
|
|
|
+|1|104@FP16, 48@FP32| 15,891| 9,174| 1.73| 1.00| 1.00|
|
|
|
+|4|104@FP16, 48@FP32| 53,417| 32,035| 1.67| 3.36| 3.49|
|
|
|
+|8|104@FP16, 48@FP32| 115,032| 58,703| 1.96| 7.24| 6.40|
|
|
|
|
|
|
The following table shows the results for WaveGlow:
|
|
|
|
|
|
|Number of GPUs|Batch size per GPU|Number of samples used with mixed precision|Number of samples used with FP32|Speed-up with mixed precision|Multi-GPU weak scaling with mixed precision|Multi-GPU weak scaling with FP32|
|
|
|
|---:|---:|---:|---:|---:|---:|---:|
|
|
|
-|1| 10@FP16, 4@FP32 | 81,503 | 36,671 | 2.22 | 1.00 | 1.00 |
|
|
|
-|4| 10@FP16, 4@FP32 | 275,803 | 124,504 | 2.22 | 3.38 | 3.40 |
|
|
|
-|8| 10@FP16, 4@FP32 | 583,887 | 264,903 | 2.20 | 7.16 | 7.22 |
|
|
|
+|1| 10@FP16, 4@FP32 | 105,873| 33,761| 3.14| 1.00| 1.00|
|
|
|
+|4| 10@FP16, 4@FP32 | 364,471| 118,254| 3.08| 3.44| 3.50|
|
|
|
+|8| 10@FP16, 4@FP32 | 690,909| 222,794| 3.10| 6.53| 6.60|
|
|
|
|
|
|
To achieve these same results, follow the steps in the [Quick Start Guide](#quick-start-guide).
|
|
|
|
|
|
@@ -648,99 +755,128 @@ The following table shows the expected training time for convergence for Tacotro
|
|
|
|
|
|
|Number of GPUs|Batch size per GPU|Time to train with mixed precision (Hrs)|Time to train with FP32 (Hrs)|Speed-up with mixed precision|
|
|
|
|---:|---:|---:|---:|---:|
|
|
|
-|1| 104@FP16, 48@FP32 | 193 | 312 | 1.62 |
|
|
|
-|4| 104@FP16, 48@FP32 | 53 | 85 | 1.58 |
|
|
|
-|8| 104@FP16, 48@FP32 | 31 | 45 | 1.47 |
|
|
|
+|1| 104@FP16, 48@FP32| 181| 333| 1.84|
|
|
|
+|4| 104@FP16, 48@FP32| 53| 88| 1.66|
|
|
|
+|8| 104@FP16, 48@FP32| 31| 48| 1.56|
|
|
|
|
|
|
The following table shows the expected training time for convergence for WaveGlow (1001 epochs):
|
|
|
|
|
|
|Number of GPUs|Batch size per GPU|Time to train with mixed precision (Hrs)|Time to train with FP32 (Hrs)|Speed-up with mixed precision|
|
|
|
|---:|---:|---:|---:|---:|
|
|
|
-|1| 10@FP16, 4@FP32 | 347 | 768 | 2.21 |
|
|
|
-|4| 10@FP16, 4@FP32 | 106 | 231 | 2.18 |
|
|
|
-|8| 10@FP16, 4@FP32 | 49 | 105 | 2.16 |
|
|
|
+|1| 10@FP16, 4@FP32 | 249| 793| 3.18|
|
|
|
+|4| 10@FP16, 4@FP32 | 78| 233| 3.00|
|
|
|
+|8| 10@FP16, 4@FP32 | 48| 127| 2.98|
|
|
|
|
|
|
#### Inference performance results
|
|
|
|
|
|
The following tables show inference statistics for the Tacotron2 and WaveGlow
|
|
|
-text-to-speech system, gathered from 1000 inference runs, on 1 V100 and 1 T4,
|
|
|
+text-to-speech system, gathered from 1000 inference runs, on 1x A100, 1x V100 and 1x T4,
|
|
|
respectively. Latency is measured from the start of Tacotron 2 inference to
|
|
|
the end of WaveGlow inference. The tables include average latency, latency standard
|
|
|
deviation, and latency confidence intervals. Throughput is measured
|
|
|
as the number of generated audio samples per second. RTF is the real-time factor
|
|
|
which tells how many seconds of speech are generated in 1 second of compute.
|
|
|
|
|
|
-##### Inference performance: NVIDIA DGX-1 (1x V100 16G)
|
|
|
+##### Inference performance: NVIDIA DGX A100 (1x A100 40GB)
|
|
|
|
|
|
-|Batch size|Input length|Precision|Avg latency (s)|Latency std (s)|Latency confidence interval 90% (s)|Latency confidence interval 95% (s)|Latency confidence interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg mels generated (81 mels=1 sec of speech)|Avg audio length (s)|Avg RTF|
|
|
|
-|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|
|
|
|
-|1| 128| FP16| 1.27| 0.06| 1.34| 1.38| 1.41| 121,190| 1.37| 603| 7.00| 5.51|
|
|
|
-|4| 128| FP16| 2.32| 0.09| 2.42| 2.45| 2.59| 277,711| 2.03| 628| 7.23| 3.12|
|
|
|
-|1| 128| FP32| 1.70| 0.05| 1.77| 1.79| 1.84| 88,650| 1.00| 590| 6.85| 4.03|
|
|
|
-|4| 128| FP32| 4.56| 0.12| 4.72| 4.77| 4.87| 136,518| 1.00| 608| 7.06| 1.55|
|
|
|
+Our results were obtained by running the `inference-script-name.sh` inferencing
|
|
|
+benchmarking script in the PyTorch-20.06-py3 NGC container on NVIDIA DGX A100 (1x A100 40GB) GPU.
|
|
|
|
|
|
-##### Inference performance: NVIDIA T4
|
|
|
+|Batch size|Input length|Precision|WN channels|Avg latency (s)|Latency std (s)|Latency confidence interval 50% (s)|Latency confidence interval 90% (s)|Latency confidence interval 95% (s)|Latency confidence interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg mels generated (81 mels=1 sec of speech)|Avg audio length (s)|Avg RTF|
|
|
|
+|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|
|
|
|
+|1| 128| FP16| 256| 0.80| 0.02| 0.80| 0.83| 0.84| 0.86| 192,086| 1.08| 602| 6.99| 8.74|
|
|
|
+|4| 128| FP16| 256| 1.05| 0.03| 1.05| 1.09| 1.10| 1.13| 602,856| 1.20| 619| 7.19| 6.85|
|
|
|
+|1| 128| FP32| 256| 0.87| 0.02| 0.87| 0.90| 0.91| 0.93| 177,210| 1.00| 601| 6.98| 8.02|
|
|
|
+|4| 128| FP32| 256| 1.27| 0.03| 1.26| 1.31| 1.32| 1.35| 500,458| 1.00| 620| 7.20| 5.67|
|
|
|
+|1| 128| FP16| 512| 0.87| 0.02| 0.87| 0.90| 0.92| 0.94| 176,135| 1.12| 601| 6.98| 8.02|
|
|
|
+|4| 128| FP16| 512| 1.37| 0.03| 1.36| 1.42| 1.43| 1.45| 462,691| 1.32| 619| 7.19| 5.25|
|
|
|
+|1| 128| FP32| 512| 0.98| 0.03| 0.98| 1.02| 1.03| 1.07| 156,586| 1.00| 602| 6.99| 7.13|
|
|
|
+|4| 128| FP32| 512| 1.81| 0.05| 1.79| 1.86| 1.90| 1.93| 351,465| 1.00| 620| 7.20| 3.98|
|
|
|
+
|
|
|
+##### Inference performance: NVIDIA DGX-1 (1x V100 16GB)
|
|
|
|
|
|
-|Batch size|Input length|Precision|Avg latency (s)|Latency std (s)|Latency confidence interval 90% (s)|Latency confidence interval 95% (s)|Latency confidence interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg mels generated (81 mels=1 sec of speech)|Avg audio length (s)|Avg RTF|
|
|
|
-|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|
|
|
|
-|1| 128| FP16| 3.13| 0.13| 3.28| 3.36| 3.46| 49,276| 1.26| 602| 6.99| 2.24|
|
|
|
-|4| 128| FP16| 11.98| 0.42| 12.44| 12.70| 13.29| 53,676| 1.23| 628| 7.29| 0.61|
|
|
|
-|1| 128| FP32| 3.88| 0.12| 4.04| 4.09| 4.19| 38,964| 1.00| 591| 6.86| 1.77|
|
|
|
-|4| 128| FP32| 14.34| 0.42| 14.89| 15.08| 15.55| 43,489| 1.00| 609| 7.07| 0.49|
|
|
|
+|Batch size|Input length|Precision|WN channels|Avg latency (s)|Latency std (s)|Latency confidence interval 50% (s)|Latency confidence interval 90% (s)|Latency confidence interval 95% (s)|Latency confidence interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg mels generated (81 mels=1 sec of speech)|Avg audio length (s)|Avg RTF|
|
|
|
+|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|
|
|
|
+|1| 128| FP16| 256| 1.14| 0.07| 1.12| 1.20| 1.33| 1.40| 136,069| 1.58| 602| 6.99| 6.13|
|
|
|
+|4| 128| FP16| 256| 1.52| 0.05| 1.52| 1.58| 1.61| 1.65| 416,688| 1.72| 619| 7.19| 4.73|
|
|
|
+|1| 128| FP32| 256| 1.79| 0.06| 1.78| 1.86| 1.89| 1.99| 86,175| 1.00| 602| 6.99| 3.91|
|
|
|
+|4| 128| FP32| 256| 2.61| 0.07| 2.61| 2.71| 2.74| 2.78| 242,656| 1.00| 619| 7.19| 2.75|
|
|
|
+|1| 128| FP16| 512| 1.25| 0.08| 1.23| 1.32| 1.44| 1.50| 124,057| 1.90| 602| 6.99| 5.59|
|
|
|
+|4| 128| FP16| 512| 2.11| 0.06| 2.10| 2.19| 2.22| 2.29| 300,505| 2.37| 620| 7.20| 3.41|
|
|
|
+|1| 128| FP32| 512| 2.36| 0.08| 2.35| 2.46| 2.54| 2.61| 65,239| 1.00| 601| 6.98| 2.96|
|
|
|
+|4| 128| FP32| 512| 5.00| 0.14| 4.96| 5.18| 5.26| 5.42| 126,810| 1.00| 618| 7.18| 1.44|
|
|
|
|
|
|
|
|
|
+##### Inference performance: NVIDIA T4
|
|
|
+
|
|
|
+|Batch size|Input length|Precision|WN channels|Avg latency (s)|Latency std (s)|Latency confidence interval 50% (s)|Latency confidence interval 90% (s)|Latency confidence interval 95% (s)|Latency confidence interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg mels generated (81 mels=1 sec of speech)|Avg audio length (s)|Avg RTF|
|
|
|
+|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|---:|
|
|
|
+|1| 128| FP16| 256| 1.23| 0.05| 1.22| 1.29| 1.33| 1.42| 125,397| 2.46| 602| 6.99| 5.68|
|
|
|
+|4| 128| FP16| 256| 2.85| 0.08| 2.84| 2.96| 2.99| 3.07| 222,672| 1.90| 620| 7.20| 2.53|
|
|
|
+|1| 128| FP32| 256| 3.03| 0.10| 3.02| 3.14| 3.19| 3.32| 50,900| 1.00| 602| 6.99| 2.31|
|
|
|
+|4| 128| FP32| 256| 5.41| 0.15| 5.38| 5.61| 5.66| 5.85| 117,325| 1.00| 620| 7.20| 1.33|
|
|
|
+|1| 128| FP16| 512| 1.75| 0.08| 1.73| 1.87| 1.91| 1.98| 88,319| 2.79| 602| 6.99| 4.00|
|
|
|
+|4| 128| FP16| 512| 4.59| 0.13| 4.57| 4.77| 4.83| 4.94| 138,226| 2.84| 620| 7.20| 1.57|
|
|
|
+|1| 128| FP32| 512| 4.87| 0.14| 4.86| 5.03| 5.13| 5.27| 31,630| 1.00| 602| 6.99| 1.44|
|
|
|
+|4| 128| FP32| 512| 13.02| 0.37| 12.96| 13.53| 13.67| 14.13| 48,749| 1.00| 620| 7.20| 0.55|
|
|
|
+
|
|
|
Our results were obtained by running the `./run_latency_tests.sh` script in
|
|
|
-the PyTorch-19.09-py3 NGC container. Please note that to reproduce the results,
|
|
|
+the PyTorch-20.06-py3 NGC container. Please note that to reproduce the results,
|
|
|
you need to provide pretrained checkpoints for Tacotron 2 and WaveGlow. Please
|
|
|
edit the script to provide your checkpoint filenames.
|
|
|
|
|
|
|
|
|
-To compare with inference performance on CPU with TorchScript, benchmark inference on CPU using `./run_latency_tests_cpu.sh` script and get the performance numbers for batch size 1 and 4. Intel's optimization for PyTorch on CPU are added, you need to set "export OMP_NUM_THREADS=num physical cores" based on your CPU's core number, for your reference: https://software.intel.com/content/www/us/en/develop/articles/maximize-tensorflow-performance-on-cpu-considerations-and-recommendations-for-inference.html
|
|
|
+To compare with inference performance on CPU with TorchScript, benchmark inference on CPU using `./run_latency_tests_cpu.sh` script and get the performance numbers for batch size 1 and 4. Intel's optimization for PyTorch on CPU are added, you need to set `export OMP_NUM_THREADS=<num physical cores>` based on your CPU's core number, for your reference: https://software.intel.com/content/www/us/en/develop/articles/maximize-tensorflow-performance-on-cpu-considerations-and-recommendations-for-inference.html
|
|
|
|
|
|
|
|
|
## Release notes
|
|
|
|
|
|
### Changelog
|
|
|
|
|
|
-March 2019
|
|
|
-* Initial release
|
|
|
+June 2020
|
|
|
+* Updated performance tables to include A100 results
|
|
|
|
|
|
-June 2019
|
|
|
-* AMP support
|
|
|
-* Data preprocessing for Tacotron 2 training
|
|
|
-* Fixed dropouts on LSTMCells
|
|
|
+March 2020
|
|
|
+* Added Tacotron 2 and WaveGlow inference using TensorRT Inference Server with custom TensorRT backend in `trtis_cpp`
|
|
|
+* Added Conversational AI demo script in `notebooks/conversationalai`
|
|
|
+* Fixed loading CUDA RNG state in `load_checkpoint()` function in `train.py`
|
|
|
+* Fixed FP16 export to TensorRT in `trt/README.md`
|
|
|
|
|
|
-July 2019
|
|
|
-* Changed measurement units for Tacotron 2 training and inference performance
|
|
|
-benchmarks from input tokes per second to output mel-spectrograms per second
|
|
|
-* Introduced batched inference
|
|
|
-* Included warmup in the inference script
|
|
|
+January 2020
|
|
|
+* Updated batch sizes and performance results for Tacotron 2.
|
|
|
|
|
|
-August 2019
|
|
|
-* Fixed inference results
|
|
|
-* Fixed initialization of Batch Normalization
|
|
|
+December 2019
|
|
|
+* Added export and inference scripts for TensorRT. See [Tacotron2 TensorRT README](trt/README.md).
|
|
|
|
|
|
-September 2019
|
|
|
-* Introduced inference statistics
|
|
|
+November 2019
|
|
|
+* Implemented training resume from checkpoint
|
|
|
+* Added notebook for running Tacotron 2 and WaveGlow in TRTIS.
|
|
|
|
|
|
October 2019
|
|
|
* Tacotron 2 inference with torch.jit.script
|
|
|
|
|
|
-November 2019
|
|
|
-* Implemented training resume from checkpoint
|
|
|
-* Added notebook for running Tacotron 2 and WaveGlow in TRTIS.
|
|
|
+September 2019
|
|
|
+* Introduced inference statistics
|
|
|
|
|
|
-December 2019
|
|
|
-* Added export and inference scripts for TensorRT. See [Tacotron2 TensorRT README](trt/README.md).
|
|
|
+August 2019
|
|
|
+* Fixed inference results
|
|
|
+* Fixed initialization of Batch Normalization
|
|
|
+
|
|
|
+July 2019
|
|
|
+* Changed measurement units for Tacotron 2 training and inference performance
|
|
|
+benchmarks from input tokes per second to output mel-spectrograms per second
|
|
|
+* Introduced batched inference
|
|
|
+* Included warmup in the inference script
|
|
|
+
|
|
|
+June 2019
|
|
|
+* AMP support
|
|
|
+* Data preprocessing for Tacotron 2 training
|
|
|
+* Fixed dropouts on LSTMCells
|
|
|
+
|
|
|
+March 2019
|
|
|
+* Initial release
|
|
|
|
|
|
-January 2020
|
|
|
-* Updated batch sizes and performance results for Tacotron 2.
|
|
|
|
|
|
-March 2020
|
|
|
-* Added Tacotron 2 and WaveGlow inference using TensorRT Inference Server with custom TensorRT backend in `trtis_cpp`
|
|
|
-* Added Conversational AI demo script in `notebooks/conversationalai`
|
|
|
-* Fixed loading CUDA RNG state in `load_checkpoint()` function in `train.py`
|
|
|
-* Fixed FP16 export to TensorRT in `trt/README.md`
|
|
|
|
|
|
### Known issues
|
|
|
|

 Przemek Strzelczyk
Przemek Strzelczyk
{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}
