|
|
@@ -13,11 +13,10 @@ This subfolder of the Jasper for PyTorch repository contains scripts for deploy
|
|
|
- [Performance](#performance)
|
|
|
* [Inference Benchmarking in Triton Inference Server](#inference-benchmarking-in-triton-inference-server)
|
|
|
* [Results](#results)
|
|
|
- * [Performance Analysis for Triton Inference Server: NVIDIA T4
|
|
|
-](#performance-analysis-for-triton-inference-server-nvidia-t4)
|
|
|
+ * [Performance Analysis for Triton Inference Server: NVIDIA T4](#performance-analysis-for-triton-inference-server-nvidia-t4)
|
|
|
* [Maximum batch size](#maximum-batch-size)
|
|
|
* [Batching techniques: Static versus Dynamic Batching](#batching-techniques-static-versus-dynamic)
|
|
|
- * [TensorRT, ONNX, and PyTorch JIT comparisons](#tensorrt-onnx-and-pytorch-jit-comparisons)
|
|
|
+ * [TensorRT, ONNXRT-CUDA, and PyTorch JIT comparisons](#tensorrt-onnxrt-cuda-and-pytorch-jit-comparisons)
|
|
|
- [Release Notes](#release-notes)
|
|
|
* [Changelog](#change-log)
|
|
|
* [Known issues](#known-issues)
|
|
|
@@ -327,7 +326,7 @@ Figure 5: Triton pipeline - Latency & Throughput vs Concurrency using dynamic Ba
|
|
|

|
|
|
Figure 6: Triton pipeline - Latency & Throughput vs Concurrency using dynamic Batching at maximum server batch size = 8, max_queue_delay_microseconds = 5000, input audio length = 16.7 seconds, TensorRT backend.
|
|
|
|
|
|
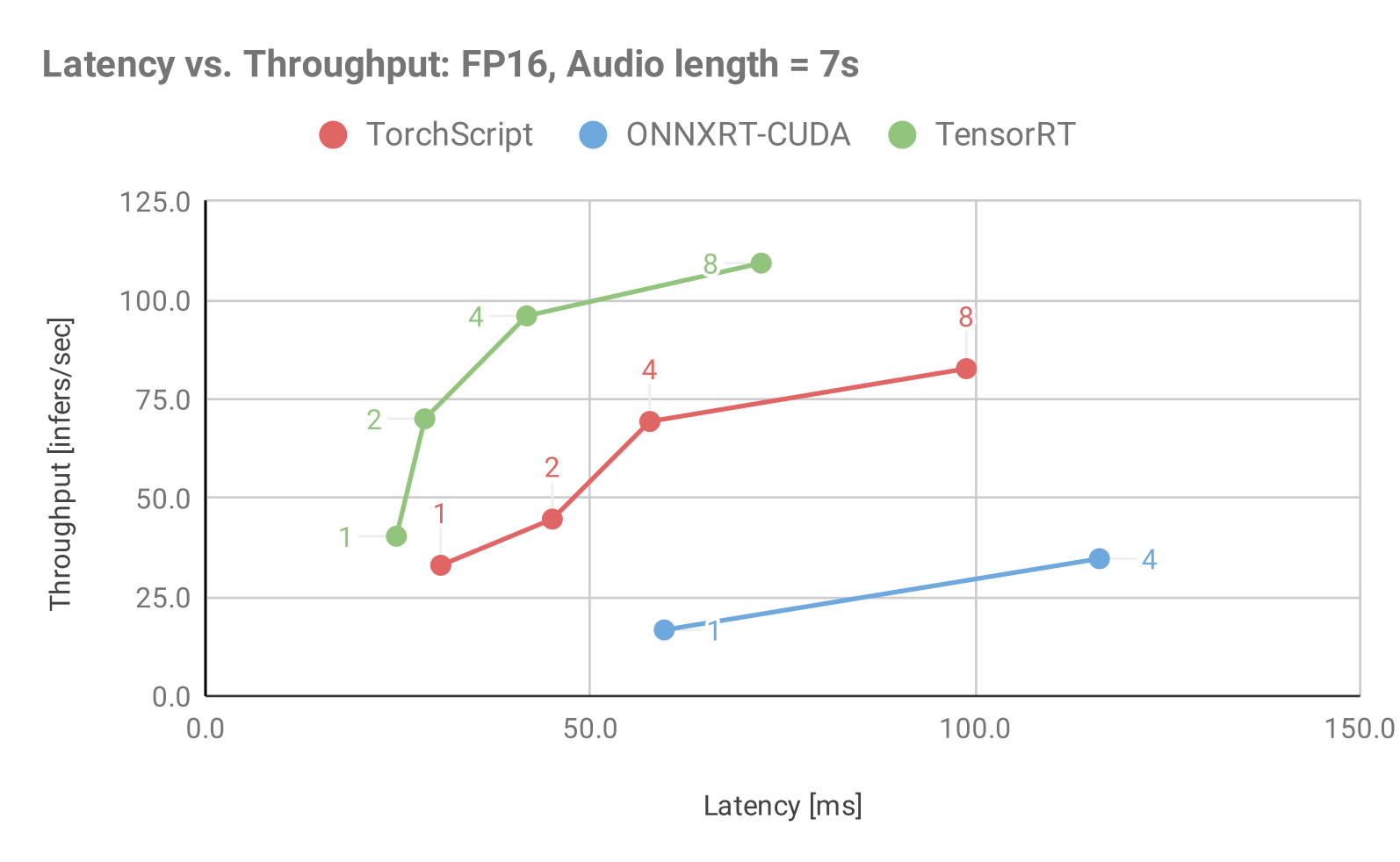
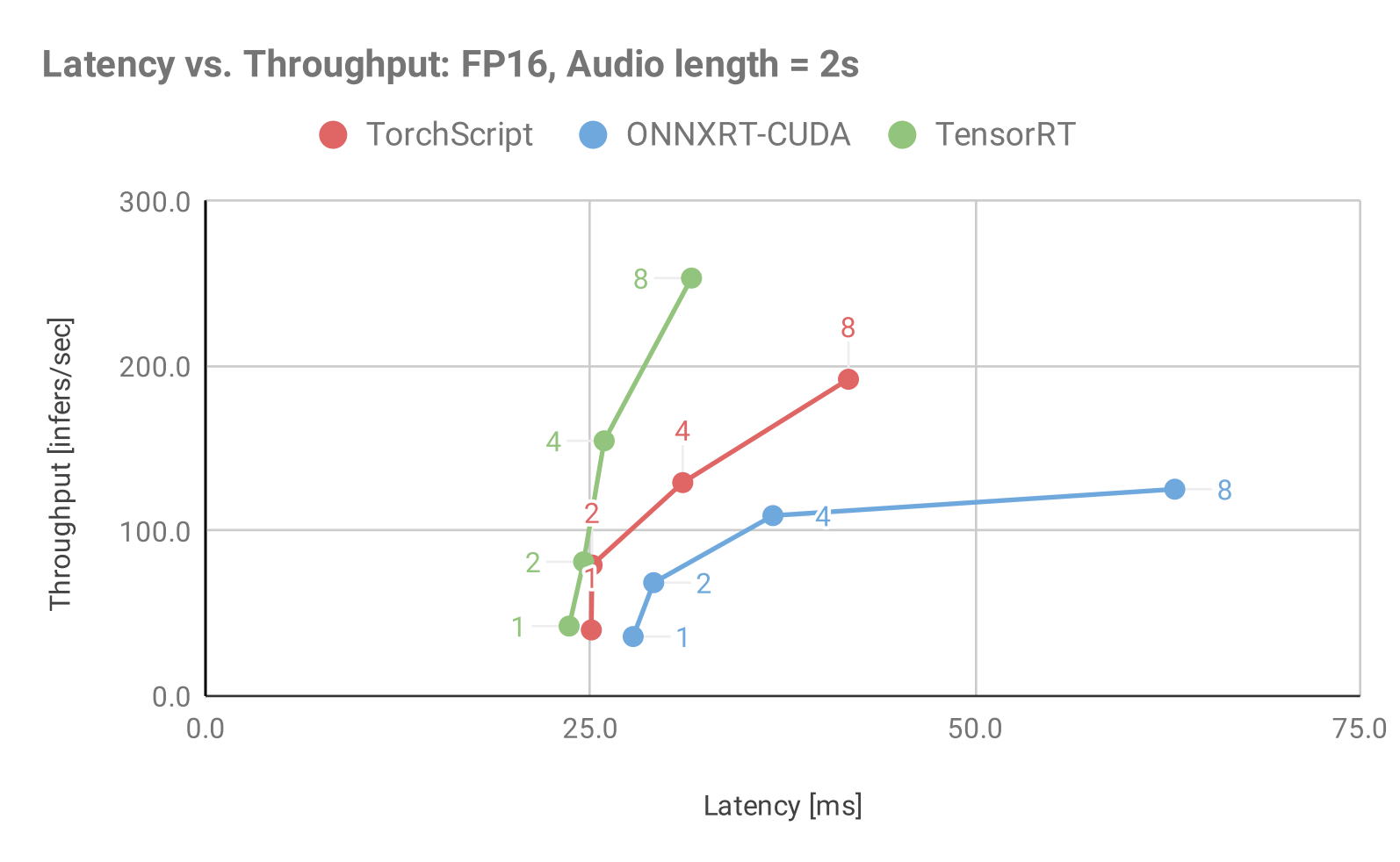
-##### TensorRT, ONNX, and PyTorch JIT comparisons
|
|
|
+##### TensorRT, ONNXRT-CUDA, and PyTorch JIT comparisons
|
|
|
|
|
|
The following tables show inference and latency comparisons across all 3 backends for mixed precision and static batching. The main observations are:
|
|
|
Increasing the batch size leads to higher inference throughput and - latency up to a certain batch size, after which it slowly saturates.
|
|
|
@@ -337,7 +336,7 @@ The longer the audio length, the lower the throughput and the higher the latency
|
|
|
|
|
|
The following table shows the throughput benchmark results for all 3 model backends in Triton Inference Server using static batching under optimal concurrency
|
|
|
|
|
|
-|Audio length in seconds|Batch Size|TensorRT (inf/s)|PyTorch (inf/s)|ONNX (inf/s)|TensorRT/PyTorch Speedup|TensorRT/Onnx Speedup|
|
|
|
+|Audio length in seconds|Batch Size|TensorRT (inf/s)|PyTorch (inf/s)|ONNXRT-CUDA (inf/s)|TensorRT/PyTorch Speedup|TensorRT/ONNXRT-CUDA Speedup|
|
|
|
|--- |--- |--- |--- |--- |--- |--- |
|
|
|
| 2.0| 1| 49.67| 55.67| 41.67| 0.89| 1.19|
|
|
|
| 2.0| 2| 98.67| 96.00| 77.33| 1.03| 1.28|
|
|
|
@@ -356,7 +355,7 @@ The following table shows the throughput benchmark results for all 3 model backe
|
|
|
|
|
|
The following table shows the throughput benchmark results for all 3 model backends in Triton Inference Server using static batching and a single concurrent request.
|
|
|
|
|
|
-|Audio length in seconds|Batch Size|TensorRT (ms)|PyTorch (ms)|ONNX (ms)|TensorRT/PyTorch Speedup|TensorRT/Onnx Speedup|
|
|
|
+|Audio length in seconds|Batch Size|TensorRT (ms)|PyTorch (ms)|ONNXRT-CUDA (ms)|TensorRT/PyTorch Speedup|TensorRT/ONNXRT-CUDA Speedup|
|
|
|
|--- |--- |--- |--- |--- |--- |--- |
|
|
|
| 2.0| 1| 23.61| 25.06| 31.84| 1.06| 1.35|
|
|
|
| 2.0| 2| 24.56| 25.11| 37.54| 1.02| 1.53|
|

 gkarch
gkarch
{kind=link}

{kind=link}
{kind=link}